
Buckets
A bucket is a container for objects stored in Amazon S3. Every object is contained in a bucket. For example, if the
object named photos/puppy.jpg is stored in the awsexamplebucket1 bucket in the US West (Oregon) Region, then it
is addressable using the URL https://awsexamplebucket1.s3.us-west-2.amazonaws.com/photos/puppy.jpg.
Buckets serve several purposes:
- They organize the Amazon S3 namespace at the highest level.
- They identify the account responsible for storage and data transfer charges.
- They play a role in access control.
- They serve as the unit of aggregation for usage reporting.
You can configure buckets so that they are created in a specific AWS Region. For more information, see Accessing a Bucket. You can also configure a bucket so that every time an object is added to it, Amazon S3 generates a unique version ID and assigns it to the object. For more information, see Using Versioning.
For more information about buckets, see Working with Amazon S3 Buckets.
Objects
Objects are the fundamental entities stored in Amazon S3. Objects consist of object data and metadata. The data portion
is opaque to Amazon S3. The metadata is a set of name-value pairs that describe the object. These include some default
metadata, such as the date last modified, and standard HTTP metadata, such as Content-Type. You can also specify
custom metadata at the time the object is stored.
An object is uniquely identified within a bucket by a key (name) and a version ID. For more information, see Keys and Using Versioning.
Keys
A key is the unique identifier for an object within a bucket. Every object in a bucket has exactly one key. The
combination of a bucket, key, and version ID uniquely identify each object. So you can think of Amazon S3 as a basic
data map between "bucket + key + version" and the object itself. Every object in Amazon S3 can be uniquely addressed
through the combination of the web service endpoint, bucket name, key, and optionally, a version. For example, in the
URL https://doc.s3.amazonaws.com/2006-03-01/AmazonS3.wsdl, "doc" is the name of the bucket and
"2006-03-01/AmazonS3.wsdl" is the key.
For more information about object keys, see Object Keys.
Regions
You can choose the geographical AWS Region where Amazon S3 will store the buckets that you create. You might choose a Region to optimize latency, minimize costs, or address regulatory requirements. Objects stored in a Region never leave the Region unless you explicitly transfer them to another Region. For example, objects stored in the Europe (Ireland) Region never leave it.
Amazon S3 Data Consistency Model
Amazon S3 provides read-after-write consistency for PUTS of new objects in your S3 bucket in all Regions with one caveat. The caveat is that if you make a HEAD or GET request to a key name before the object is created, then create the object shortly after that, a subsequent GET might not return the object due to eventual consistency.
Amazon S3 offers eventual consistency for overwrite PUTS and DELETES in all Regions.
Updates to a single key are atomic. For example, if you PUT to an existing key, a subsequent read might return the old data or the updated data, but it never returns corrupted or partial data.
Amazon S3 achieves high availability by replicating data across multiple servers within AWS data centers. If a PUT request is successful, your data is safely stored. However, information about the changes must replicate across Amazon S3, which can take some time, and so you might observe the following behaviors:
- A process writes a new object to Amazon S3 and immediately lists keys within its bucket. Until the change is fully propagated, the object might not appear in the list.
- A process replaces an existing object and immediately tries to read it. Until the change is fully propagated, Amazon S3 might return the previous data.
- A process deletes an existing object and immediately tries to read it. Until the deletion is fully propagated, Amazon S3 might return the deleted data.
- A process deletes an existing object and immediately lists keys within its bucket. Until the deletion is fully propagated, Amazon S3 might list the deleted object.
Updates are key-based. There is no way to make atomic updates across keys. For example, you cannot make the update of one key dependent on the update of another key unless you design this functionality into your application.
Buckets have a similar consistency model, with the same caveats. For example, if you delete a bucket and immediately list all buckets, Amazon S3 might still appear in the list.
The following table describes the characteristics of an eventually consistent read and a consistent read:
| Eventually consistent read | Consistent read |
|---|---|
| Stale reads possible | No stale reads |
| Lowest read latency | Potential higher read latency |
| Highest read throughput | Potential lower read throughput |
Concurrent applications
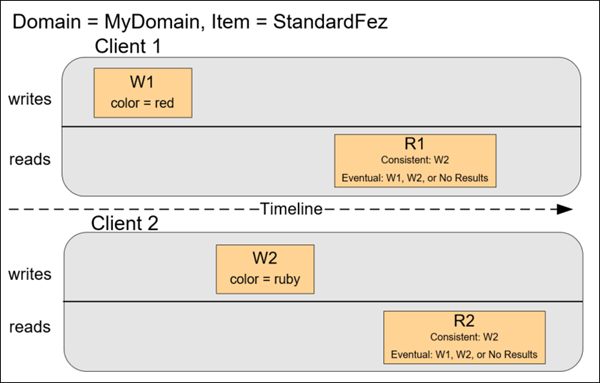
In this example, both W1 (write 1) and W2 (write 2) complete before the start of R1 (read 1) and R2 (read 2). For a
consistent read, R1 and R2 both return color = ruby. For an eventually consistent read, R1 and R2 might return
color = red or color = ruby depending on the amount of time that has elapsed.
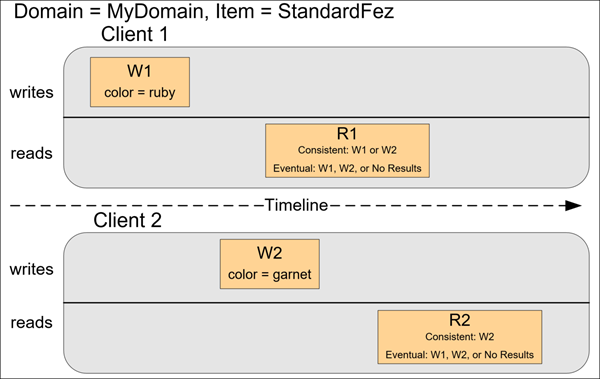
In the next example, W2 does not complete before the start of R1. Therefore, R1 might return color = ruby or
color = garnet for either a consistent read or an eventually consistent read. Also, depending on the amount of time
that has elapsed, an eventually consistent read might return no results.
For a consistent read, R2 returns color = garnet. For an eventually consistent read, R2 might return
color = ruby or color = garnet depending on the amount of time that has elapsed.
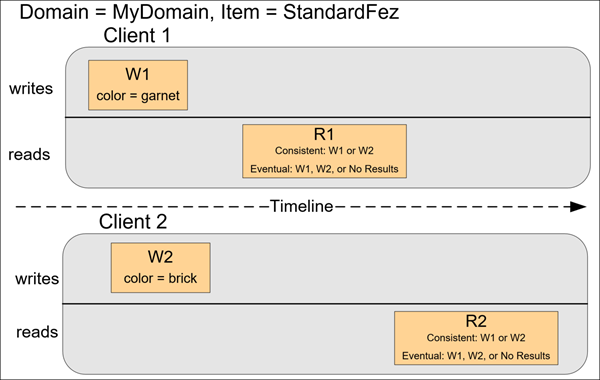
In the last example, Client 2 performs W2 before Amazon S3 returns a success for W1, so the outcome of the final value
is unknown (color = garnet or color = brick). Any subsequent reads (consistent read or eventually consistent)
might return either value. Also, depending on the amount of time that has elapsed, an eventually consistent read might
return no results.
Prefix - Listing Keys Hierarchically Using a Prefix and Delimiter
A "prefix", or "key prefix" is a logical grouping of the objects in a bucket. The prefix value is similar to a directory name that enables you to store similar data under the same directory in a bucket. Note that Amazon S3 does not have the concept of "directory". There is only objects whose keys are prefixed in a way that looks like a "directory". For example
zoo/west-side/fish/little-fish.png
There is no such directories called zoo, west-side, fish. In this case the :ref:key <concept-keys> for the
image little-fish.png is zoo/west-side/fish/, a string essentially.
The prefix and delimiter parameters limit the kind of results returned by a list operation. The prefix limits the results to only those keys that begin with the specified prefix. The delimiter causes a list operation to roll up all the keys that share a common prefix into a single summary list result.
The purpose of the prefix and delimiter parameters is to help you organize and then browse your keys hierarchically. To do this, first pick a delimiter for your bucket, such as slash (/), that doesn't occur in any of your anticipated key names. Next, construct your key names by concatenating all containing levels of the hierarchy, separating each level with the delimiter.
For example, if you were storing information about cities, you might naturally organize them by continent, then by country, then by state. Because these names do not usually contain punctuation, you might select slash (/) as the delimiter. The following examples use a slash (/) delimiter.
- Europe/France/Nouvelle-Aquitaine/Bordeaux
- North America/Canada/Quebec/Montreal
- North America/USA/Washington/Bellevue
- North America/USA/Washington/Seattle
By using Prefix and Delimiter with the list operation, you can use the hierarchy you've created to list your
data. For example, to list all the states in USA, set Delimiter='/' and Prefix='North America/USA/'.
A list request with a delimiter lets you browse your hierarchy at just one level, skipping over and summarizing the
(possibly millions of) keys nested at deeper levels. For example, assume you have a bucket (ExampleBucket) with the
following keys.
sample.jpg
photos/2006/January/sample.jpg
photos/2006/February/sample2.jpg
photos/2006/February/sample3.jpg
photos/2006/February/sample4.jpg
The sample bucket has only the sample.jpg object at the root level. To list only the root level objects in the
bucket you send a GET request on the bucket with "/" delimiter character. In response, Amazon S3 returns the
sample.jpg object key because it does not contain the "/" delimiter character. All other keys contain the
delimiter character. Amazon S3 groups these keys and return a single CommonPrefixes element with prefix value
photos/ that is a substring from the beginning of these keys to the first occurrence of the specified delimiter.